During lunch breaks (or any breaks for that matter), it’s usually not enough to discuss nerd stuff with my colleagues. Oh no, we have to take it up a notch, so naturally we play puzzle games while on our break. One of our all-time favorites is the daily New York Times (NYT) Spelling Bee https://www.nytimes.com/puzzles/spelling-bee https://www.nytimes.com/puzzles/spelling-bee .

It’s a game with simple rules: Every day, you get presented with an assortment of 7 distinct letters, arranged in a honeycomb-like pattern (one letter in the middle, and 6 surrounding it). The goal of the game is to come up with as many words using the 7 letters, with some additional limitations:
- Words must have at least 4 letters
- Words must contain the central letter
You’re free to repeat letters as many times as you want, as long as you adhere to the two limitations. For each word you can find, you get rewarded points: 4-letter words give one point, while longer words give as many points as they are long. There is, however, one more special rule: Words that contain all 7 letters at least once (so-called pangrams) give a special bonus of 7 points. Here’s an example:
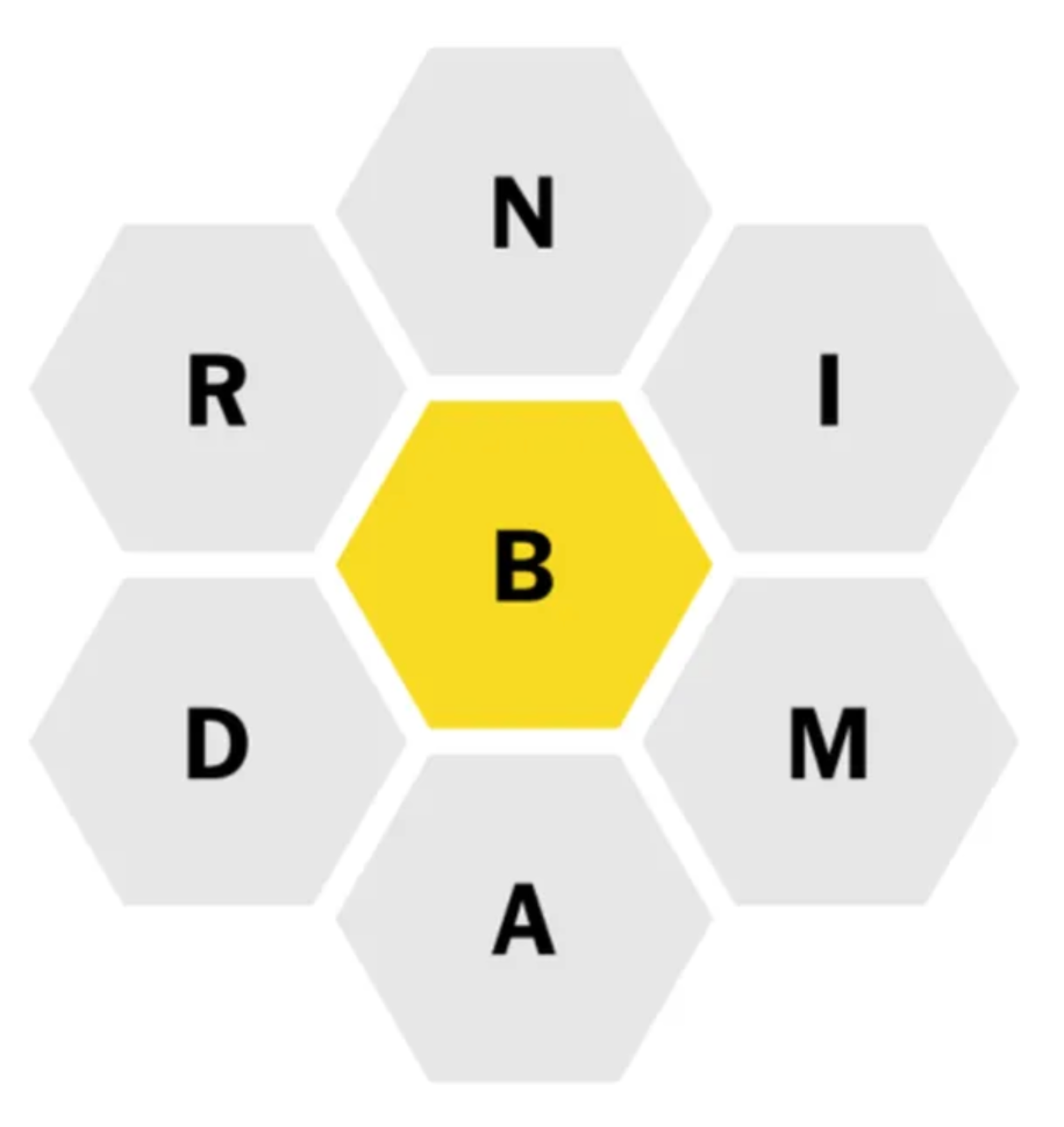
For this configuration, your goal would be to use these 7 letters to come up with as many words of length 4 or more, which must contain the letter B. There’s also one more thing I didn’t tell you: NYT Spelling Bee puzzles always contain at least one pangram!
Now that we’ve got all the rules and limitations in place, we’re gonna do what any engineer would:
Which 7 letter-configuration yields the highest (theoretically) possible score?
What is a word?
In order to find the limits of Spelling Bee, we first have to know what exactly a word is. Is ship a word? Obviously yes. How about shipping? Again yes (adding -ing is actually a common pattern to generate more words). How about coracoprocoracoid
A medical term I will not even pretend to understand.
A medical term I will not even pretend to understand.
or Brazil? While these are technically words, you would not be able to use them in Spelling Bee - the first one because it is too specialized and obscure, and the second one because it is a proper noun
Nouns which are names for a particular person, place, organization, or thing. They are always capitalized.
Nouns which are names for a particular person, place, organization, or thing. They are always capitalized.
.
So, for starters, we can’t get points for any word. It has to be reasonably well-known (which does not mean common - only excluding ultra-obscure words) and cannot be the name of a place, person, company, etc.
But first, we’ll actually need some words to begin with, which leads us to step 1 of any experiment - data collection!
Getting a dictionary
I’ve tried to find out if the people that come up with the daily puzzle have disclosed which dictionary they use, however with no luck. So, our best guess is to just get the most well-known dictionaries and use those as sources of truth. To my knowledge, the leading English dictionaries are the New Oxford American Dictionary and the Merriam-Webster Dictionary. However, in order to access these datasets, you need to pay a fee (spoiler: this ain’t happening).
So, instead of paying the mega-corporations, we’ll find a free and open-source alternative. After some googling, I’ve found the english-words Github repo, containing 479k words https://github.com/dwyl/english-words https://github.com/dwyl/english-words . That’ll do.
Now, we can start doing some Python-powered counting!
Pangrams, counts, and NLP
With a proper dataset of English words, we can easily calculate the total number of possible Spelling Bee game boards - just extract all pangrams, and multiply that number by 7 (because each pangram yields 7 possible boards, with the difference being the center letter).
def filter_pangrams(words: dict) -> list[str]:
pangrams = []
for key in words.keys():
if len(set(key)) == 7:
pangrams.append(key)
return pangrams
This gives us a nice list of 74263 pangrams and 519841 possible Spelling Bee game boards. However, this is not quite true. This list of pangrams includes some really obscure pangrams, for example aasvogel
An obsolete Afrikaans word for vulture, technically part of the Merriam-Webster English dictionary.
An obsolete Afrikaans word for vulture, technically part of the Merriam-Webster English dictionary.
. It also includes proper nouns, like Belgium.
We’ll have to trim down this list of pangrams. Let’s first solve the problem of proper nouns.
Enter WordNet
WordNet is a large lexical database of English https://wordnet.princeton.edu/ https://wordnet.princeton.edu/ . It’s a project by Princeton University, which is no longer under active development. However, it remains free to use. On the surface, it might seem like WordNet is just a dataset of words (like the one we downloaded), however it’s much more than that:
Inside of WordNet, words are grouped by their synonymity, into groups of words which denote the same concept. These groups are called synsets. There’s 117 000 of them in WordNet, and they are linked between each other through conceptual relations between the synsets. This is done by connecting more general synsets (like furniture) to increasingly specific ones (like bed).
The neat thing is that WordNet introduces two concepts: types and instances. Types refer to any common noun, while instances are proper nouns. For example, yacht is a type of ship, while Titanic is an instance of ship. We can use this property of WordNet to easily filter out our proper nouns:
def is_proper_noun(word) -> bool:
synsets = wn.synsets(word)
if not synsets:
return False # not in WordNet at all
if all(s.instance_hypernyms() for s in synsets):
return True
if word in (country.name.lower() for country in pycountry.countries):
return False
# Catch personal names not in WordNet (e.g. "liam", "emma")
if word in NAME_SET:
return True
return False
Here, the all is important for words which are both proper and common nouns (for example, the word jordan can be a country name, as well as a chamber pot). In addition, I’ve used the pycountry package as a safeguard for dual-use words, like the aforementioned jordan.
Great, we’ve deleted most of the proper nouns from our word list. Now what remains is deleting ultra-obscure words - and this is where Zipf’s law can help us.
Zipf’s law and obscure words
If you’ve ever dabbled in statistics, you’re probably familiar with Zipf’s law As with many laws, Zipf wasn’t actually the one who came up with it first. As with many laws, Zipf wasn’t actually the one who came up with it first. :
When a set of measured values is sorted in decreasing order, the value of the nth entry is often approximately inversely proportional to n.
And this is especially true for large corpora of words: The most common words occur approximately twice as often as the next most common one, three times as often as the third one, and so on.
This law got later turned into a logarithmic frequency scale (proposed by Marc Brysbaert). The goal is to map reasonable word frequencies to small positive numbers.
A word rates x on the Zipf scale when it occurs 10x times per one billion words. For example, a word that occurs once per million words is at 3.0 on the Zipf scale. A lower number indicates rarer words, with the value of 0 being words that appear once per one billion words, or less.
The Python package wordfreq implements the Zipf frequency - it’s basically just a collection of statistical data for many different corpora of languages.
So, in order to filter out some really obscure words, we can just take the Zipf frequency, and discard all words which are below a given threshold:
from wordfreq import zipf_frequency
# Must be reasonably common
if zipf_frequency(word, 'en') < THRESHOLD:
return False
With this, we’ve solved both proper nouns and obscure words. Now we can move on to producing some actual insights!
Exploring Spelling Bee
Everything is in place, let’s jump straight into analysis. All of this can be easily combined into a Python script with a couple of simple steps:
- Extract pangrams
- Remove proper nouns using WordNet
- Remove obscure words using Zipf’s law
- For each pangram and middle letter configuration:
- Find which words from the original dataset can be constructed using the pangram letters, containing the center letter
- Calculate score based on the found words
- Return all boards with their best games
All of these steps are easily implemented in Python.
Note: While the code for the described algorithm is trivial, I’ve used one trick to make my life a bit easier: Step 4 is sped up usingmultiprocessing, specifically the Pool.imap() function in order to assign pangram calculations to parallel workers based on the number of available CPU cores. It’s embarrassingly parallel, so the effort to implement is minimal but the gains in execution speed are substantial.
Best games and longest words
After implementing this simple algorithm, and trying it out with a few different Zipf’s frequencies (ZF), here’s what we get:
| Exclude Prop. Nouns | ZF | # of pangrams | # of valid words | Longest word | Best board | Best score |
|---|---|---|---|---|---|---|
| No | 0 | 74263 | 367517 | humuhumunukunukuapuaa |
anestri |
13377 |
| Yes | 0 | 24364 | 107907 | coccidioidomycosis |
antisera |
5670 |
| Yes | 1 | 16667 | 76053 | coccidioidomycosis |
antisera |
4030 |
| Yes | 2 | 10350 | 48382 | inconsistencies |
artesian |
2588 |
| Yes | 3 | 4378 | 21361 | inconsistencies |
scattered |
1291 |
| Yes | 4 | 990 | 5872 | consciousness |
desperate |
515 |
| Yes | 4.5 | 352 | 2480 | entertainment |
characters |
268 |
| Yes | 5 | 80 | 803 | association |
interesting |
81 |
e is the best central letter. This is not surprising, given that e is the most common letter in the English language.
Well, there you have it! Allowing every possible word to be valid, the longest pangram we get is a whopping 21 characters long - humuhumunukunukuapuaa - the Hawaiian name for the Reef triggerfish
Funnily enough, also the name of a song in the movie High School Musical 2: https://www.youtube.com/watch?v=30OwdMs4E9A
Funnily enough, also the name of a song in the movie High School Musical 2: https://www.youtube.com/watch?v=30OwdMs4E9A
.
If we tighten the rules a bit, using larger and larger Zipf frequencies (and thus allowing only more common words to be valid), we progressively decrease the best possible score.
Personally, it seems like 4-4.5 would be a good value for the Zipf frequency threshold in order to get something similar to the NYT Spelling Bee game. Here’s the full list of words for the case of ZF=4 - the theoretical game with the pangram desperate and the letter e as the center letter:
Full word list for pangram desperate with center letter e
(Pangrams denoted with *)
| Word | Length | ZF | Points |
|---|---|---|---|
addressed |
9 | 4.26 | 9 |
addresses |
9 | 4.13 | 9 |
depressed |
9 | 4.14 | 9 |
desperate* |
9 | 4.32 | 16 |
separated* |
9 | 4.3 | 16 |
appeared |
8 | 4.83 | 8 |
arrested |
8 | 4.64 | 8 |
prepared |
8 | 4.74 | 8 |
repeated |
8 | 4.28 | 8 |
separate |
8 | 4.83 | 8 |
stressed |
8 | 4.18 | 8 |
adapted |
7 | 4.17 | 7 |
address |
7 | 4.91 | 7 |
appears |
7 | 4.84 | 7 |
dressed |
7 | 4.42 | 7 |
dresses |
7 | 4.05 | 7 |
prepare |
7 | 4.55 | 7 |
pressed |
7 | 4.12 | 7 |
readers |
7 | 4.41 | 7 |
retreat |
7 | 4.13 | 7 |
started |
7 | 5.39 | 7 |
starter |
7 | 4.02 | 7 |
stepped |
7 | 4.2 | 7 |
streets |
7 | 4.66 | 7 |
trapped |
7 | 4.19 | 7 |
treated |
7 | 4.71 | 7 |
appear |
6 | 4.85 | 6 |
arrest |
6 | 4.55 | 6 |
assess |
6 | 4.07 | 6 |
assets |
6 | 4.56 | 6 |
deeper |
6 | 4.3 | 6 |
desert |
6 | 4.4 | 6 |
estate |
6 | 4.82 | 6 |
papers |
6 | 4.61 | 6 |
parade |
6 | 4.16 | 6 |
passed |
6 | 4.92 | 6 |
passes |
6 | 4.45 | 6 |
pepper |
6 | 4.14 | 6 |
reader |
6 | 4.34 | 6 |
repeat |
6 | 4.49 | 6 |
speeds |
6 | 4.05 | 6 |
spread |
6 | 4.81 | 6 |
stated |
6 | 4.74 | 6 |
states |
6 | 5.52 | 6 |
street |
6 | 5.28 | 6 |
stress |
6 | 4.73 | 6 |
tastes |
6 | 4.08 | 6 |
tested |
6 | 4.48 | 6 |
traded |
6 | 4.15 | 6 |
trades |
6 | 4.04 | 6 |
treats |
6 | 4.06 | 6 |
added |
5 | 5.16 | 5 |
areas |
5 | 5.15 | 5 |
asset |
5 | 4.23 | 5 |
dated |
5 | 4.29 | 5 |
dates |
5 | 4.54 | 5 |
dress |
5 | 4.76 | 5 |
paper |
5 | 5.07 | 5 |
peers |
5 | 4.02 | 5 |
press |
5 | 5.16 | 5 |
raped |
5 | 4.08 | 5 |
rated |
5 | 4.3 | 5 |
rates |
5 | 4.88 | 5 |
reads |
5 | 4.25 | 5 |
seats |
5 | 4.53 | 5 |
seeds |
5 | 4.28 | 5 |
spare |
5 | 4.28 | 5 |
speed |
5 | 5.0 | 5 |
state |
5 | 5.78 | 5 |
steps |
5 | 4.73 | 5 |
taste |
5 | 4.73 | 5 |
tears |
5 | 4.47 | 5 |
tests |
5 | 4.67 | 5 |
trade |
5 | 5.12 | 5 |
treat |
5 | 4.75 | 5 |
trees |
5 | 4.69 | 5 |
area |
4 | 5.46 | 1 |
dare |
4 | 4.31 | 1 |
date |
4 | 5.22 | 1 |
dead |
4 | 5.19 | 1 |
dear |
4 | 4.77 | 1 |
deep |
4 | 5.05 | 1 |
deer |
4 | 4.12 | 1 |
ears |
4 | 4.36 | 1 |
ease |
4 | 4.34 | 1 |
east |
4 | 5.16 | 1 |
peer |
4 | 4.14 | 1 |
pets |
4 | 4.08 | 1 |
rape |
4 | 4.48 | 1 |
rare |
4 | 4.77 | 1 |
rate |
4 | 5.14 | 1 |
read |
4 | 5.54 | 1 |
rear |
4 | 4.43 | 1 |
rest |
4 | 5.23 | 1 |
seat |
4 | 4.82 | 1 |
seed |
4 | 4.37 | 1 |
sees |
4 | 4.59 | 1 |
sept |
4 | 4.35 | 1 |
sets |
4 | 4.69 | 1 |
step |
4 | 5.13 | 1 |
tape |
4 | 4.44 | 1 |
tear |
4 | 4.35 | 1 |
test |
4 | 5.19 | 1 |
tree |
4 | 4.85 | 1 |
TOTAL |
515 |
Beyond a raw score, another way we can look at the data is finding the games which have the most pangrams. Here’s a list of them, for different Zipf thresholds (obviously, ties exist so I’ve just picked the first result for each ZF):
| Zipf threshold | Pangram | Center letter | # pangrams |
|---|---|---|---|
| 2 | artesian |
e |
27 |
| 3 | argentine |
r |
12 |
| 4 | accident |
a |
4 |
| 4.5 | actions |
o |
3 |
| 5 | include |
i |
2 |
argentine does not refer to the country of Argentina (which would make it a proper noun), but rather it is a synonym for silver or silvery.
Worst games
After taking a look at the best and most satisfying games, which yield high scores and multiple pangrams, we can also flip the script and find the absolute bottom of the barrel: games with only one 7-letter pangram! These games are easy to find, as the maximum score you can have here is 14 (7 points for a 7 letter word, plus an additional 7 points for the pangram bonus) - this is also the minimum amount of points one can have in a “valid” Spelling Bee game.
| Zipf threshold | Pangram | Center letter |
|---|---|---|
| 2 | azimuth |
z |
| 3 | jukebox |
x |
| 4 | injured |
j |
| 4.5 | various |
* |
| 5 | century |
y |
For ZF=4.5, this is actually an interesting result: the pangram various delivers a dead-end game regardless of the center letter!
Here are also some games with complete solutions consisting of two words (max score is 15):
Game score distributions
Since we have all of this data, we can also look at the game score distributions across all pangrams (considering only the best possible center letter for each pangram) for the different Zipf frequencies. To that end, I’ve made an interactive chart you can play around with:
Note: The NYT-like band (50-300 - these are arbitrarily chosen based on my experience with the game) suggests a Zipf threshold of around 4-4.5 as the sweet spot for generating a game. It’s still strict enough to keep ultra-obscure words out, while at the same time offering some challenging games.Conclusion - This game is the bees knees!
It turns out that you can do something that’s even more nerdy than playing NYT Spelling Bee - spending your free time reverse-engineering it.
Does any of this help us win at Spelling Bee? Not really - turns out knowing the theoretical limits of this game doesn’t help you find the words faster. But, the next time I spend my lunch break playing, I’ll at least know that somewhere out there, there’s a Hawaiian fish worth 28 points - and that the NYT will never let me use it.
And finally, to answer our initial question:
The highest possible Spelling Bee score:515points, the pangram isdesperate, and the central letter ise. Completely useless information? Yes. Absolutely worth the hassle? Also yes.